Aggregation and decimation
Aggregation and decimation are two complementary strategies Connhex uses to speed up data retrieval.
Decimation is an operation performed upon every request received. It consists in reducing the amount of data returned to the client, by applying a transformation function. Aggregation is a periodical job: it fetches data from the raw messages' database, applies transformations through aggregation functions and updates secondary databases.
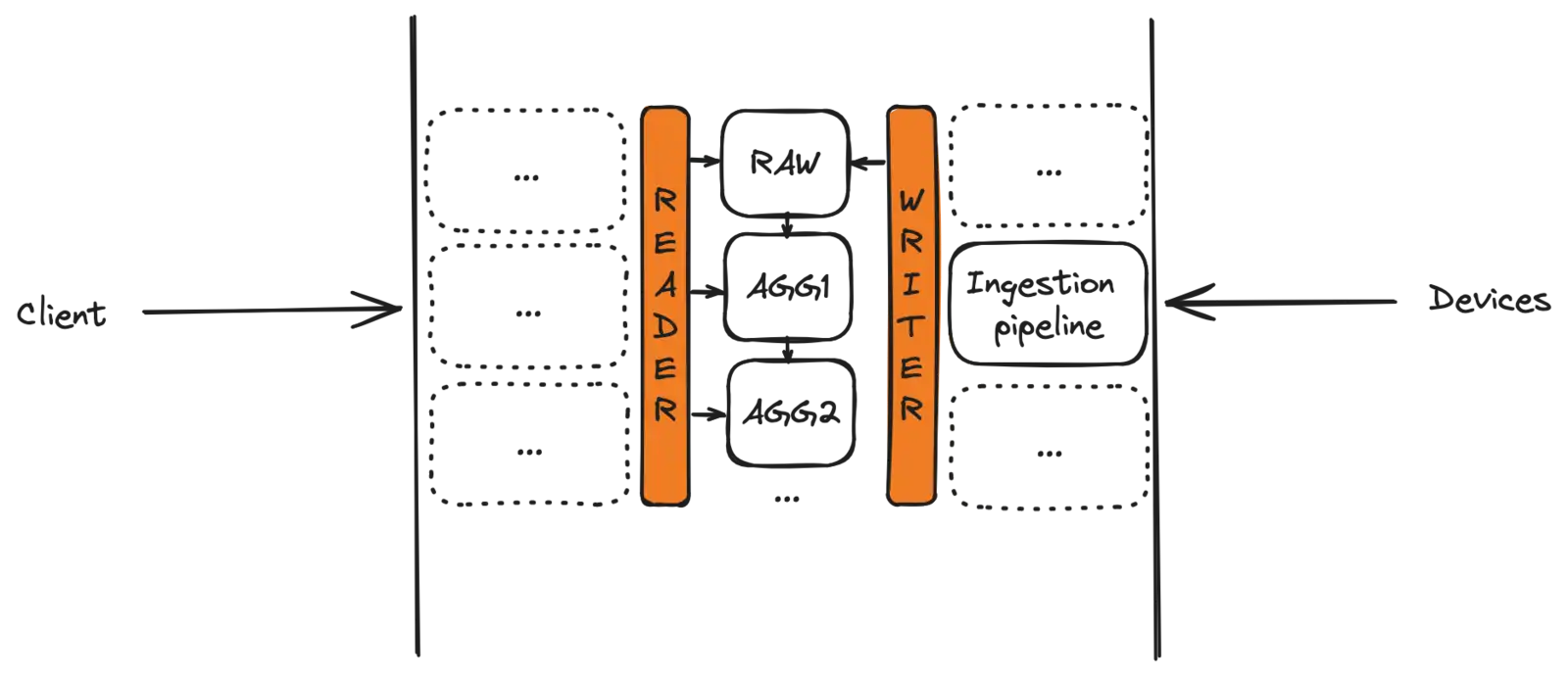
Both operations are performed transparently: decimation operates on a reader level, automatically selecting the right aggregation level for the incoming request. Aggregation, on the other hand, consists in periodically moving data: writes are always performed on the same database.
Decimation
Decimation offers a convenient way to request data points over large intervals, where raw data would be impossible to transmit and handle.
Based on the granularity specified in the request, Connhex automatically selects the optimal table to query. Data is then processed, according to the transformation function specified (see "Aggregation algorithms").
Imagine having a device that samples a variable twice a minute: requesting a year of measurements (for example, to create a trend chart) translates to more than 1.000.000 (yes, that's a million) data points.
By leveraging decimation, you can first request a rougher series (e.g. the average value for each day) and only increase granularity as the interval gets shorter.
The decimation period is specified by {{int}}{{granularity}} (i.e. 1d to request one sample every day, 15m to request 4 samples an hour, ...): supported granularity values are specified in the table below.
| Granularity | ID |
|---|---|
| Second | 's' |
| Minute | 'm' |
| Hour | 'h' |
| Day | 'd' |
| Week | 'w' |
| Month | 'M' |
| Year | 'y' |
Aggregation
Aggregation is used to minimize latency related to database access - caused by querying tables with large amounts of data. Once aggregation stages have been defined, databases are automatically kept in sync by Connhex Core: aggregated tables are continuously populated with transformed values.
The number and granularity of aggregation stages are chosen during the installation process. If the need for additional aggregation stages comes up, please contact us.
Transformations can use different algorithms: the following section provides an outline.
Aggregation algorithms
| Algorithm | ID |
|---|---|
| Min | 'min' |
| Max | 'max' |
| Average | 'avg' |
| Sum | 'sum' |
| StandardDeviation | 'stddev' |
| Variance | 'variance' |
Query params
The following table outlines the parameters that can be used in core queries. For a complete list, refer to the API.
| Parameter | Example | Notes |
|---|---|---|
| from | 1701212400 | Optional: Start timestamp (ms). Usage is strongly suggested performance-wise. |
| to | 1701269756 | Optional: end timestamp (ms). Usage is strongly suggested performance-wise. |
| ds | '1m' | Granularity. See Decimation for possible values. |
| dsv | 'v' | Optional: data point type. Possible values are: v (number), vb (boolean), vs (string). Defaults to v. |
| dsf | 'avg' | Aggregation algorithm. See Aggregation algorithms for possible values. |
| name | 'urn:cpt:edge:ser:cpt001:network-packets-dropped' | Metric URN. |
| subtopic | 'cpt.edge.sysm.data' | Metric subtopic. |
| format | 'messages' | Optional: target table space. Defaults to messages. |
| limit | 500 | Optional: number of data points to be retrieved. Defaults to 1000. |
Query example
from=1701212400&to=1701269756&ds=1m&dsv=v&dsf=avg&name=urn:cpt:edge:ser:cpt001:network-packets-dropped&subtopic=cpt.edge.sysm.data&format=messages&limit=1500